
AgentDish directory
evaluation
Accepted listings with this tag.
| Listing | Category | Score | Trend | Checked | |
|---|---|---|---|---|---|
#33
↓ -2
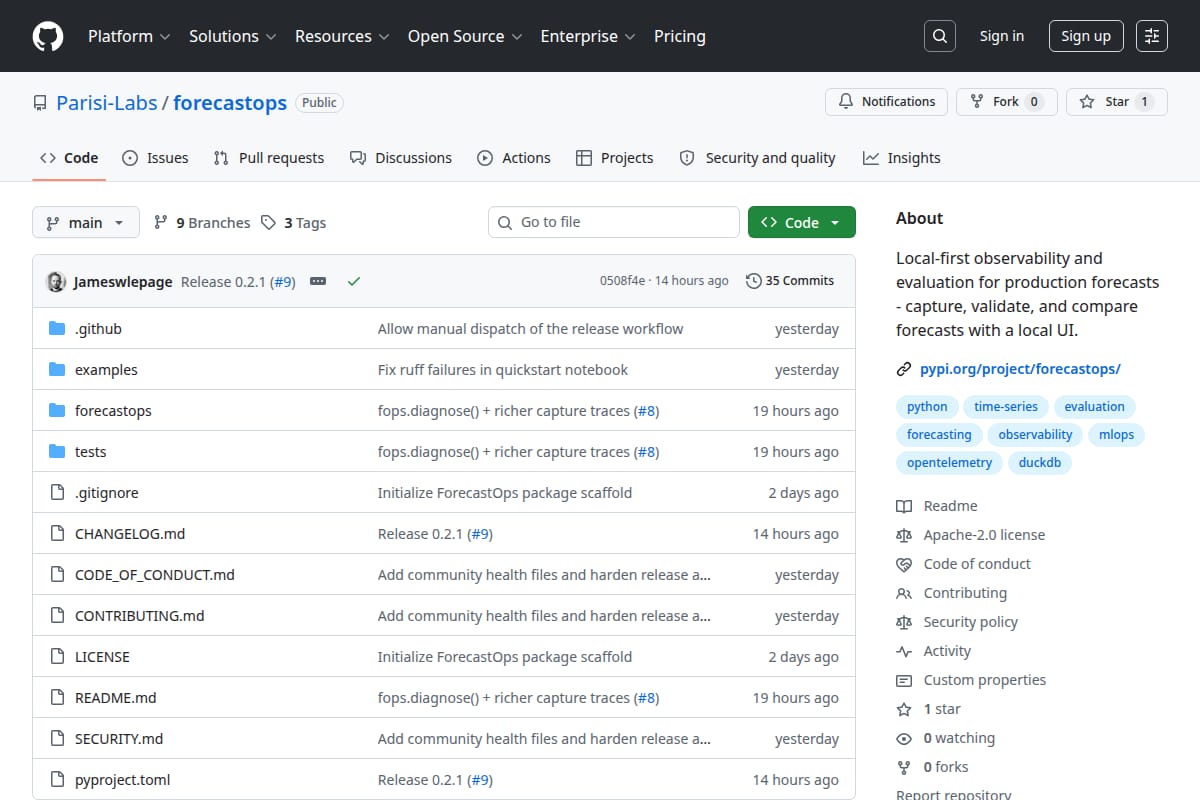
ForecastOps
Local-first observability and evaluation layer for production forecasts. Captures forecasts, validates them, computes horizon-aware metrics, and serves a read-only local UI for comparing runs. |
Developer Tools / MLOps / Observability | 90 | ↓ -2 | 34 days ago | Details |
|
#51
→ 0
ReactBench
ReactBench is a benchmark for evaluating coding agents on realistic React work, with published scores, cost comparisons, and example tasks focused on production-grade frontend issues. |
Developer Tools / Code Assistant | 89 | → 0 | 45 hours ago | Details |
#62
→ 0
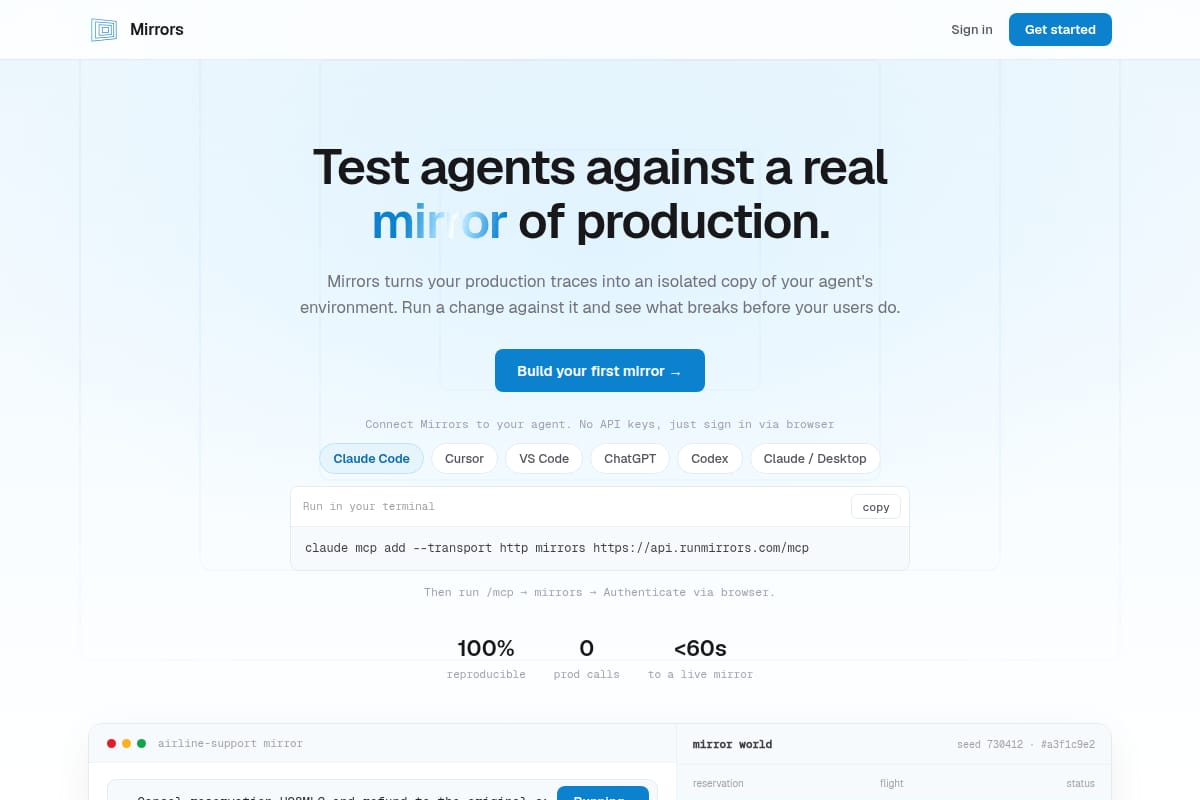
Mirrors
Mirrors turns production traces into an isolated, runnable copy of an AI agent’s environment so teams can replay workflows, reproduce bugs, and test changes safely before shipping. |
Developer Tools / AI Agent Testing | 89 | → 0 | 14 days ago | Details |
#163
↓ -3
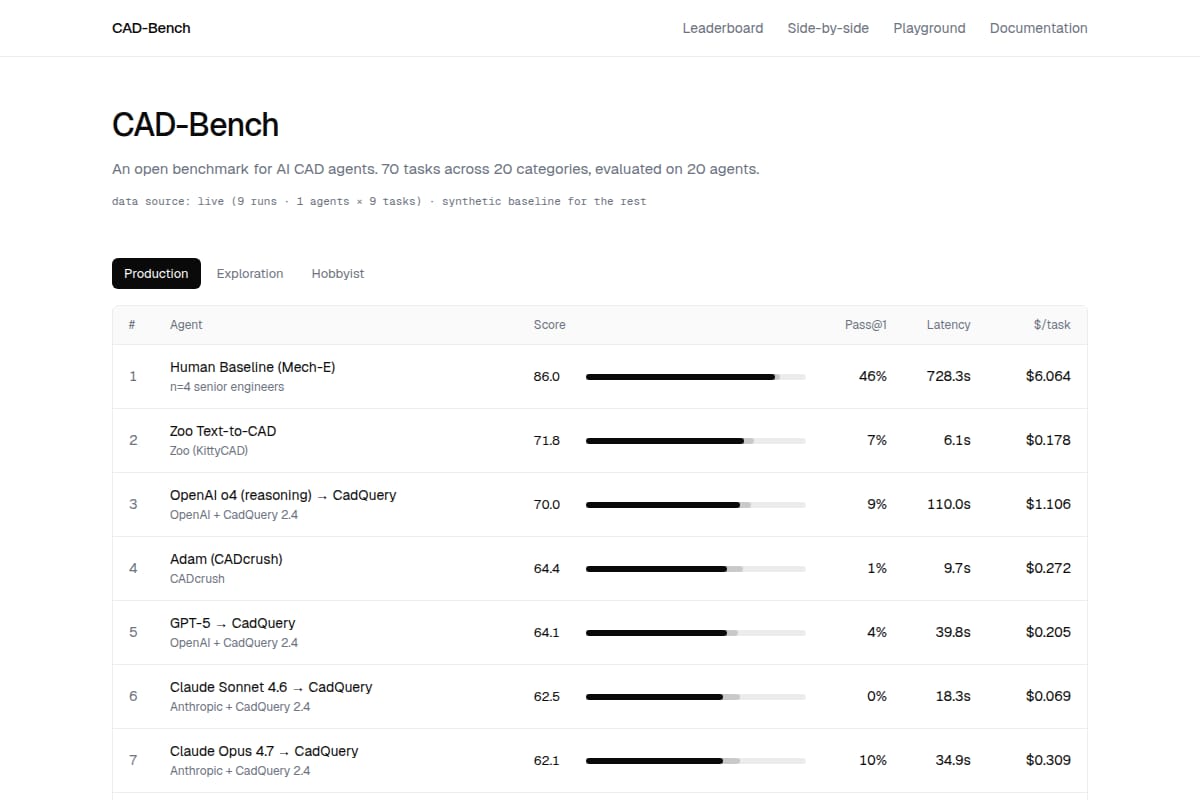
CAD-Bench
An open benchmark and leaderboard for AI CAD agents, with 308 prompts across 20 categories and layered scoring for geometry, engineering, manufacturability, and cognition. |
Research / Knowledge Work | 88 | ↓ -3 | 69 days ago | Details |
#168
↓ -3
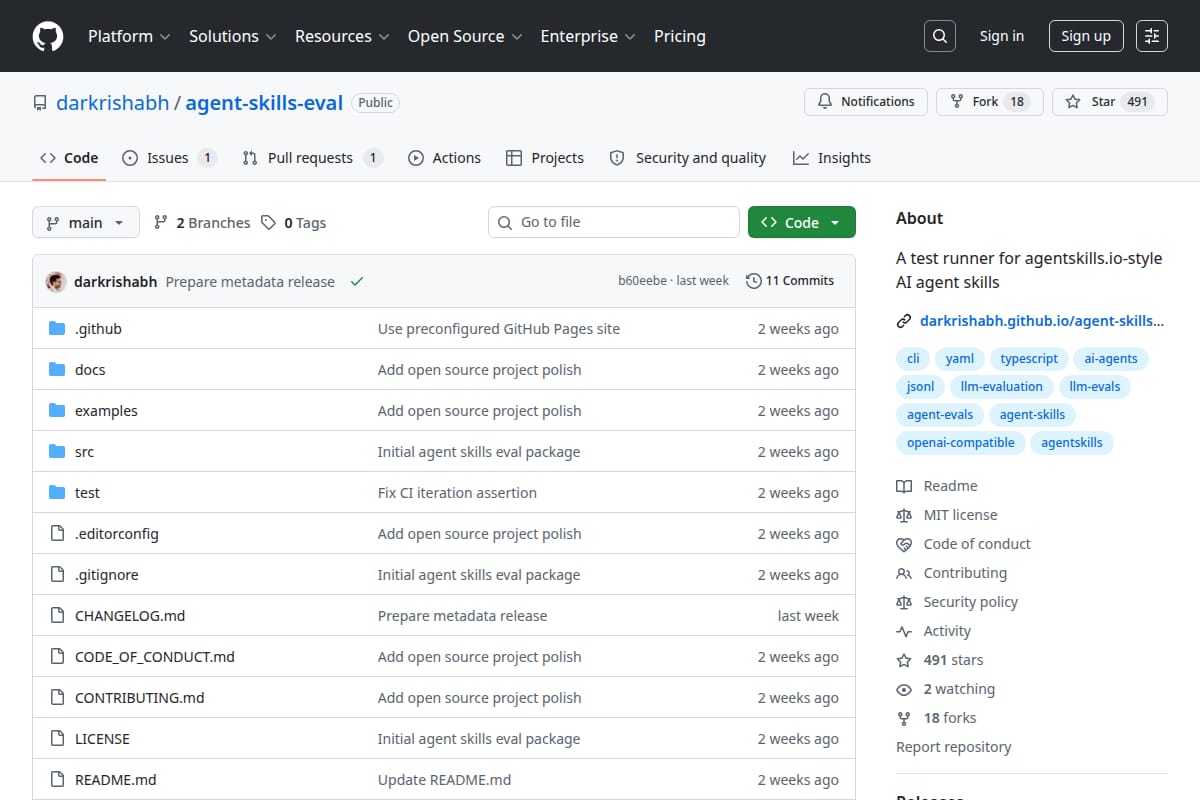
agent-skills-eval
A TypeScript CLI and SDK for testing whether Agent Skills improve model outputs by running with-skill vs baseline evaluations and generating reports. |
Developer Tools / AI Evaluation | 88 | ↓ -3 | 71 days ago | Details |
#366
↑ +555
Alignment Whack-a-Mole
A research code repository for studying how fine-tuning can trigger verbatim recall of copyrighted books in large language models. It includes preprocessing, fine-tuning, generation, and memorization-evaluation scripts, with setup notes and example data. |
Research / Copywriting | 86 | ↑ +555 | 73 days ago | Details |
#463
↓ -6
Agent Infra
A curated GitHub resource list for production AI agent infrastructure, covering runtimes, sandboxes, tool protocols, security, observability, and evaluation. |
Developer Tools / AI Infrastructure | 84 | ↓ -6 | 11 days ago | Details |

#539
↓ -6
DeepSWE
DeepSWE is a benchmark for measuring frontier coding agents on original, long-horizon software engineering tasks. The page shows a leaderboard, methodology overview, task examples, and a full blog explaining the benchmark design and results. |
Developer Tools / AI Benchmarking | 84 | ↓ -6 | 50 days ago | Details |
#741
↓ -2
clawmark
A local Rust CLI for A/B testing two CLAUDE.md files against a fixed SWE-bench Lite smoke set, with doctor, run, and report commands. |
Developer Tools / AI Benchmarking | 82 | ↓ -2 | 29 days ago | Details |
#802
↑ +2
BOUND
BOUND is a deterministic control harness for AI agents. It sits between agent execution and the next decision, using observable evidence to choose ACCEPT, RETRY, REPLAN, or ROLLBACK. |
Developer Tool / AI Agent Framework / Control Harness | 81 | ↑ +2 | just now | Details |
#894
↑ +2
ArXiv Scholar
A zero-budget research search engine and RAG pipeline for 5,600 arXiv papers, built with free Colab processing, Qdrant free tier, and hybrid dense+sparse retrieval. |
AI / Search / RAG / Research search | 79 | ↑ +2 | 31 days ago | Details |
A GitHub example that audits LangChain’s RAG quickstart with retrieval-quality metrics, flags off-topic and out-of-distribution queries, and surfaces ranking and calibration issues with charts and results files. |
Developer Tool / RAG Evaluation | 78 | ↑ +4 | 73 days ago | Details |
#1043
→ 0
Clusy
Clusy is an agent-native notebook platform for ML and data science work in the cloud. The page says it can source data, inspect it, choose architecture and compute, and run end-to-end workflows, with a demo showing a finetuning task and follow-up work queued while the notebook runs. |
Research / Knowledge Work | 75 | → 0 | 16 days ago | Details |
A GitHub research project documenting a long-form, multi-model analysis of LLM behavior across Claude, Gemini, ChatGPT, and Grok. The repo includes an executive summary, screenplay, technical white paper, and archive of logs and chat records. |
AI Research / LLM Evaluation & Analysis | 75 | → 0 | 52 days ago | Details |
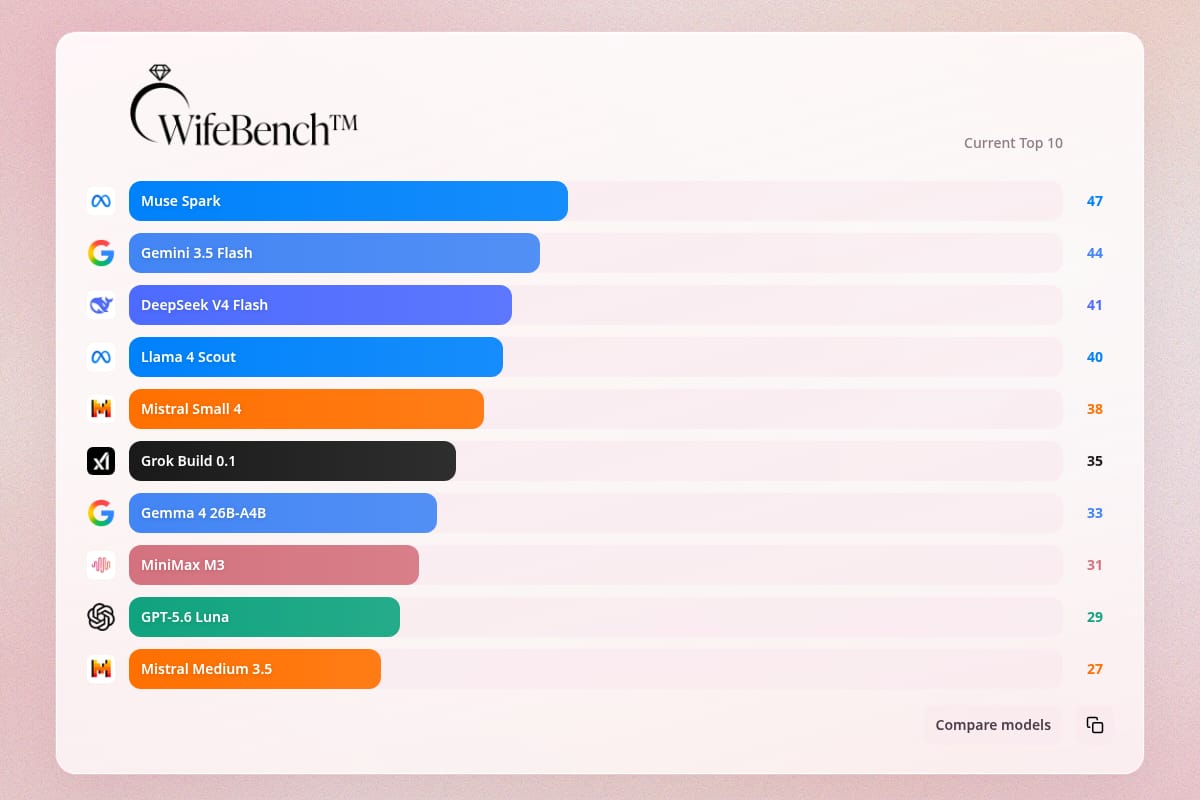
#1094
↑ +1
WifeBench
A playful benchmark dashboard that ranks LLMs based on one person's 10-question scoring process. |
Writing / Copywriting | 73 | ↑ +1 | 12 days ago | Details |