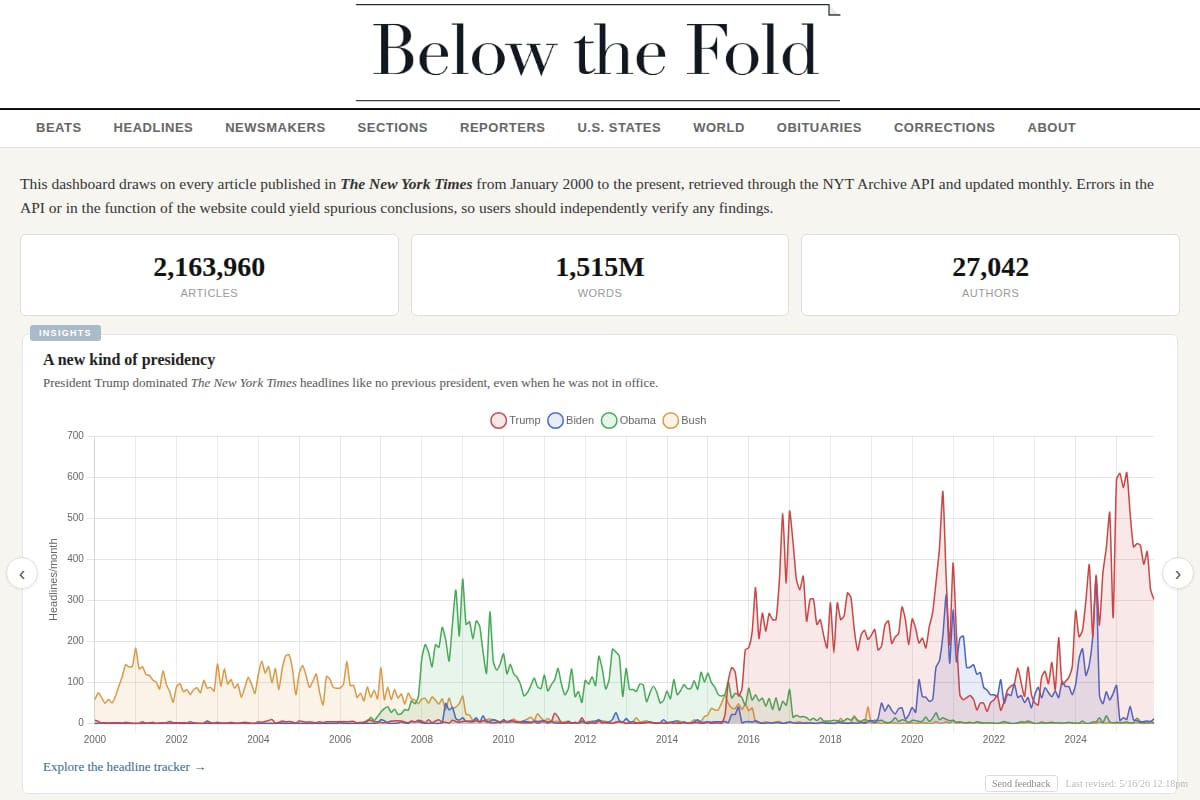
Why it was accepted
The page clearly presents a real AI-adjacent research product: a benchmark for evaluating CAD agents. It shows the scope of the task set, scoring methodology, leaderboard results, category breakdowns, and reproduction steps, which is enough for a useful public listing.