
AgentDish directory
AI research
Accepted listings with this tag.
| Listing | Category | Score | Trend | Checked | |
|---|---|---|---|---|---|
#50
↑ +124
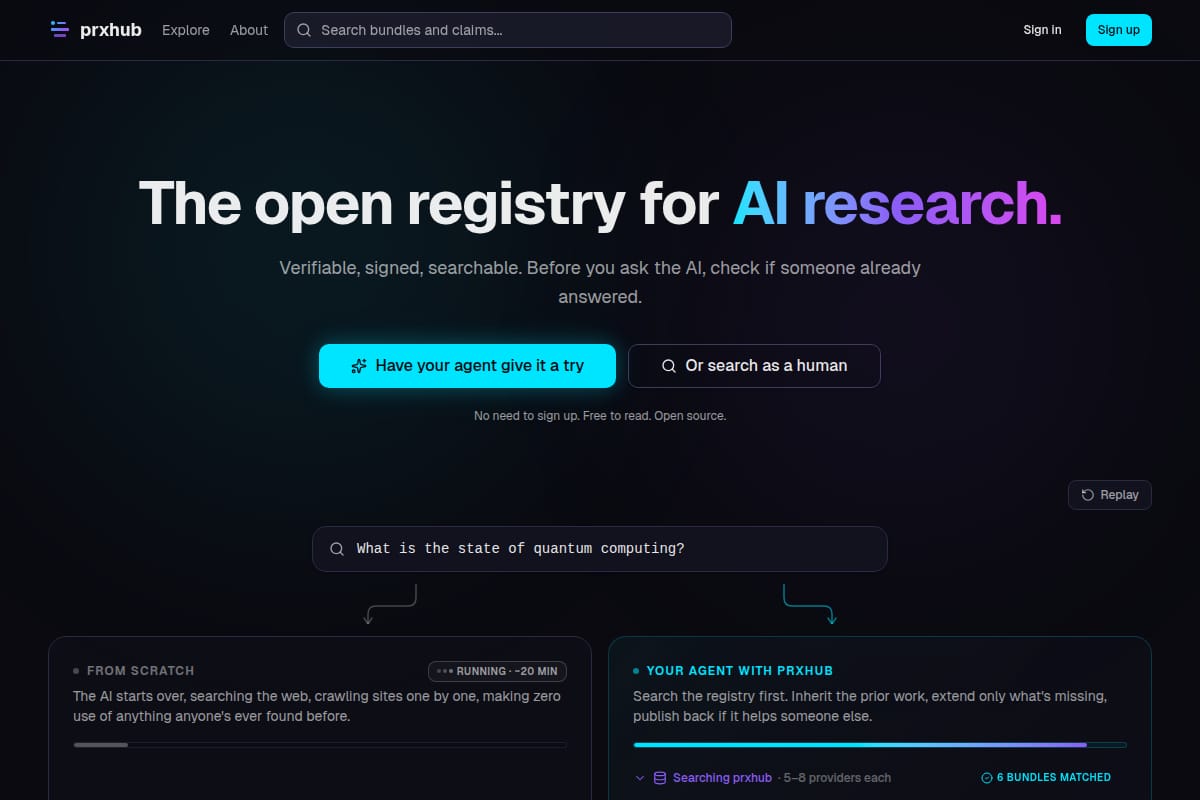
prxhub
prxhub is an open registry for AI research bundles, built around verifiable .prx artifacts, search, provenance, and agent-friendly publishing via MCP and CLI. |
Developer Tools / Code Assistant | 90 | ↑ +124 | 73 days ago | Details |
#695
↑ +100
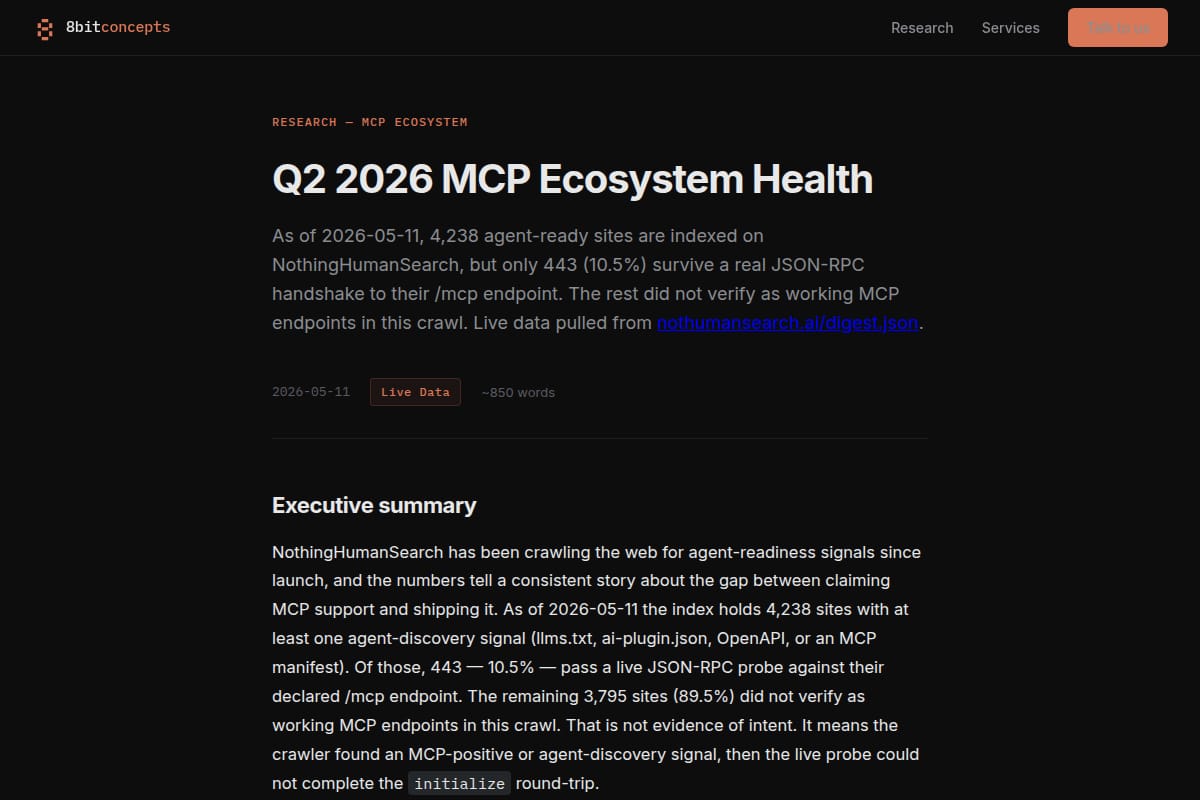
Q2 2026 MCP Ecosystem Health
A research report on the current MCP ecosystem, with live crawl numbers, verification rates, category breakdowns, and examples of both strong and weak MCP-positive sites. |
Research / AI research | 83 | ↑ +100 | 73 days ago | Details |

An early-access AI research assistant that presents a cited mindmap of AI agent safety and alignment research, with expandable nodes, source-backed claims, and built-in verification checks. |
Developer Tools / Code Assistant | 81 | ↑ +2 | 16 days ago | Details |
#818
↑ +2
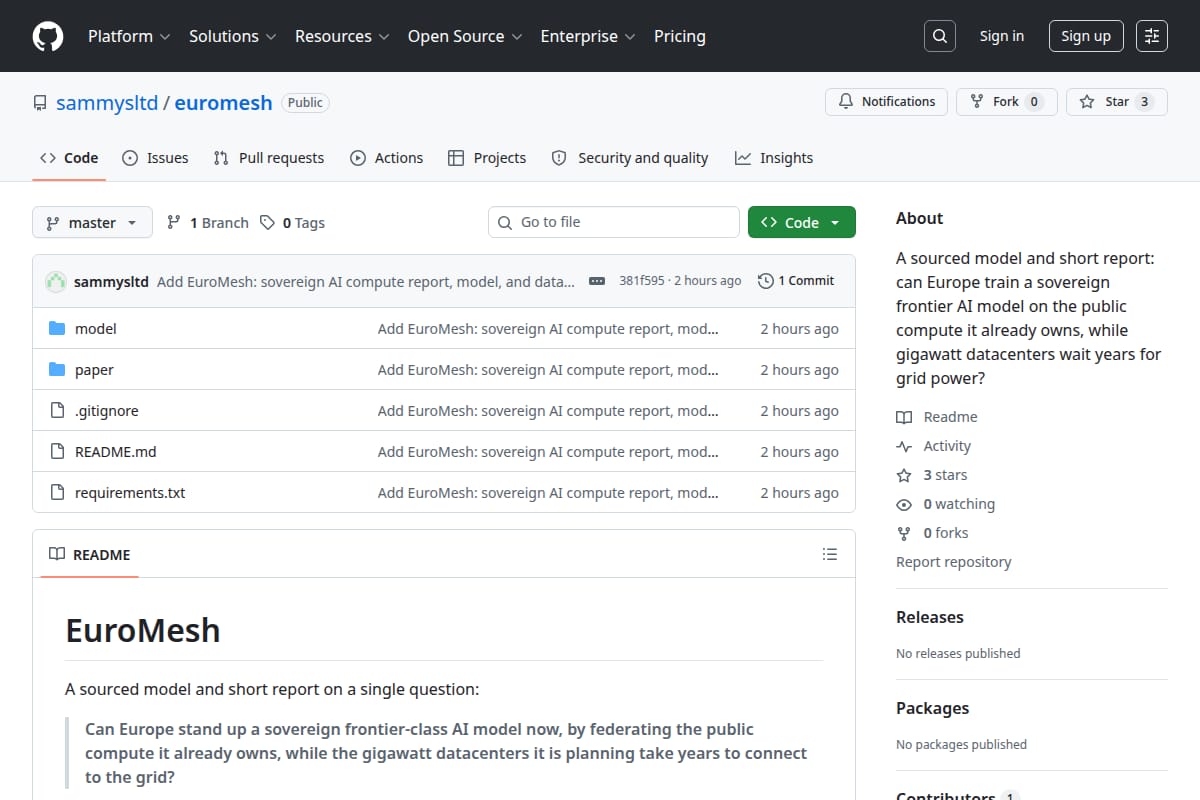
EuroMesh
A sourced model and short report exploring whether Europe could train a sovereign frontier AI model using public compute it already owns, with reproducible code, datasets, and a PDF report. |
AI Research / Analysis / Reports | 81 | ↑ +2 | 32 days ago | Details |
#835
↓ -35
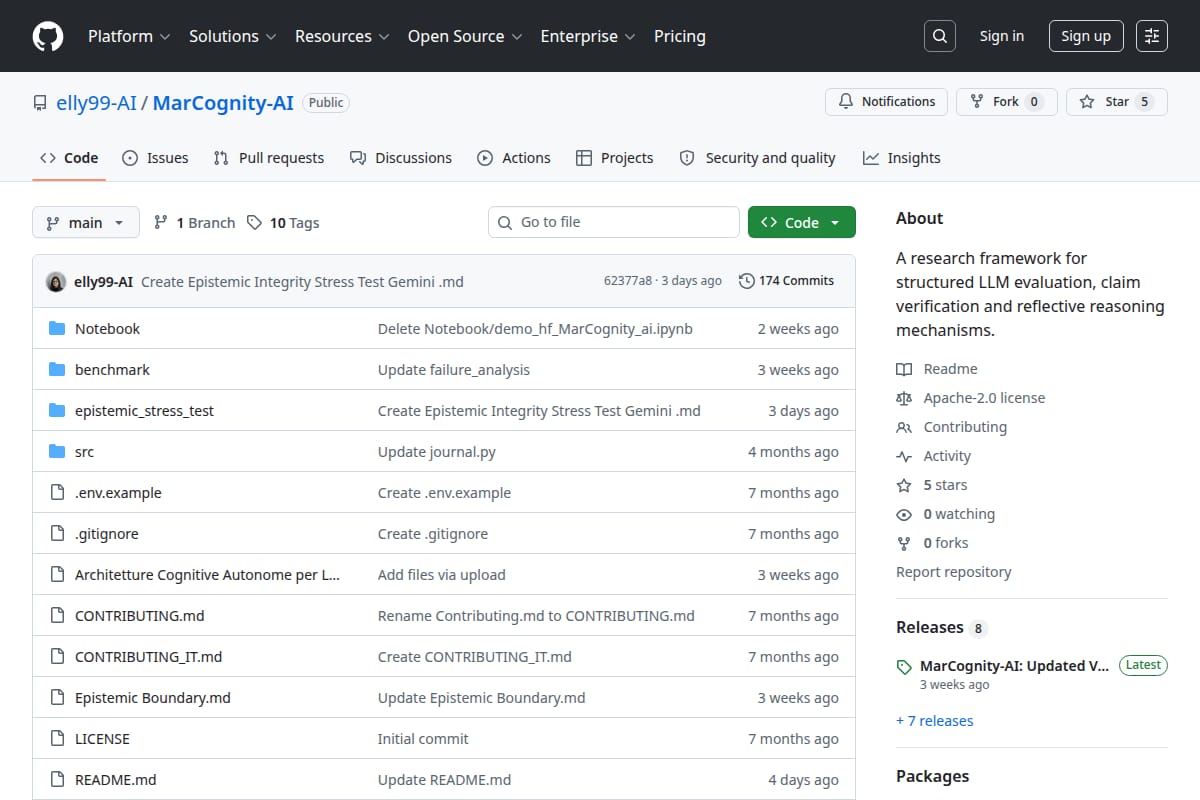
MarCognity-AI
An open-source research framework for structured LLM evaluation, claim verification, and source-grounded reflective reasoning. The repo describes modular components for retrieval, semantic scoring, skeptical claim checking, and benchmark-style epistemic assessment. |
AI Research / Evaluation / Verification Framework | 81 | ↓ -35 | 73 days ago | Details |
#940
↑ +6
MiroThinker
MiroThinker is a science-focused AI research app that emphasizes prediction, verification, and evidence-backed answers. The page also points to a MiroMind app and suggests use cases across finance, medicine, and regulation. |
AI Research / Deep Research Agent | 78 | ↑ +6 | 35 days ago | Details |

#957
↑ +6
Multi-Agent is a snake oil
An opinionated write-up on where multi-agent systems have and have not delivered value, with concrete comparisons across coding, images, CAD, and BIM, plus a description of Blade’s evidence-first architecture. |
Writing / Copywriting | 78 | ↑ +6 | 52 days ago | Details |
#964
↑ +6
Agora-1: The Multi-Agent World Model
Agora-1 is a multi-agent world model from Odyssey that simulates shared real-time environments for up to four participants, human or AI, with a focus on gaming, robotics, reinforcement learning, and foundation model research. |
AI Research / World Models | 78 | ↑ +6 | 59 days ago | Details |
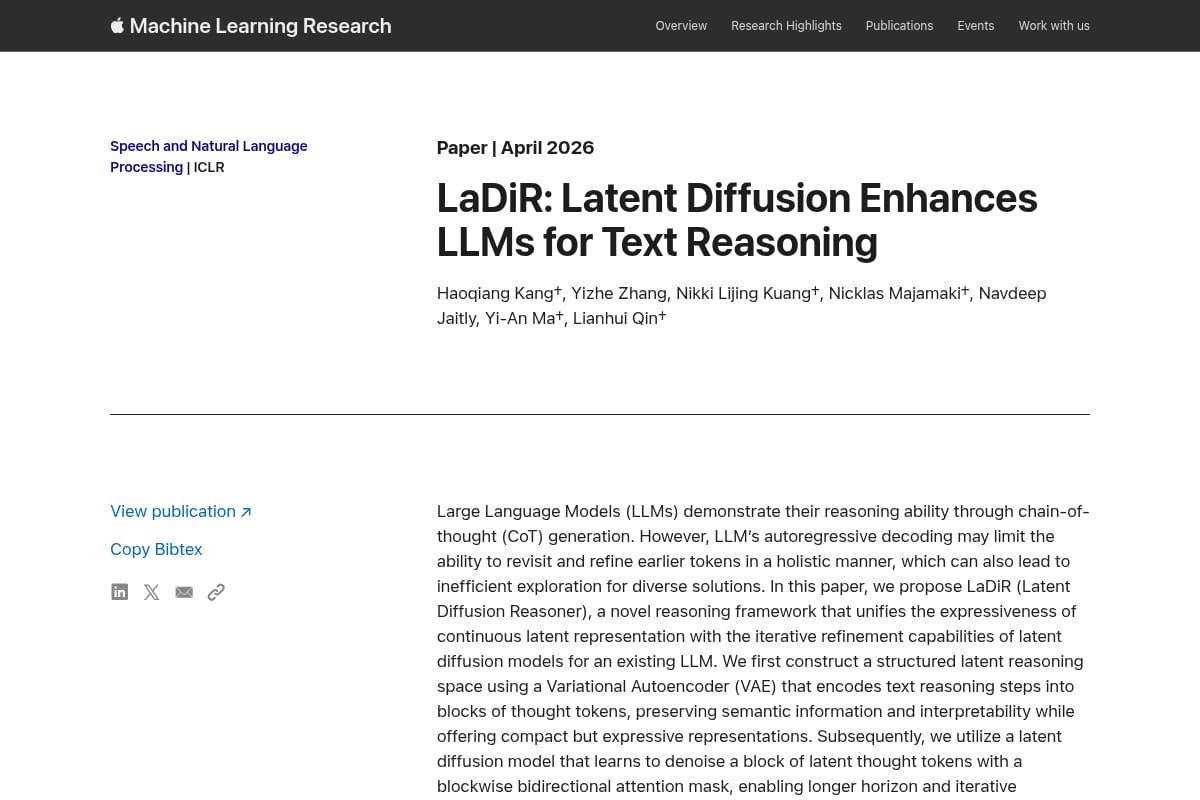
Apple Machine Learning Research paper proposing LaDiR, a reasoning framework that combines a VAE-based latent space with latent diffusion to improve LLM text reasoning and iterative refinement. |
AI Research / LLM Reasoning | 78 | ↑ +5 | 72 days ago | Details |
#1038
↓ -1
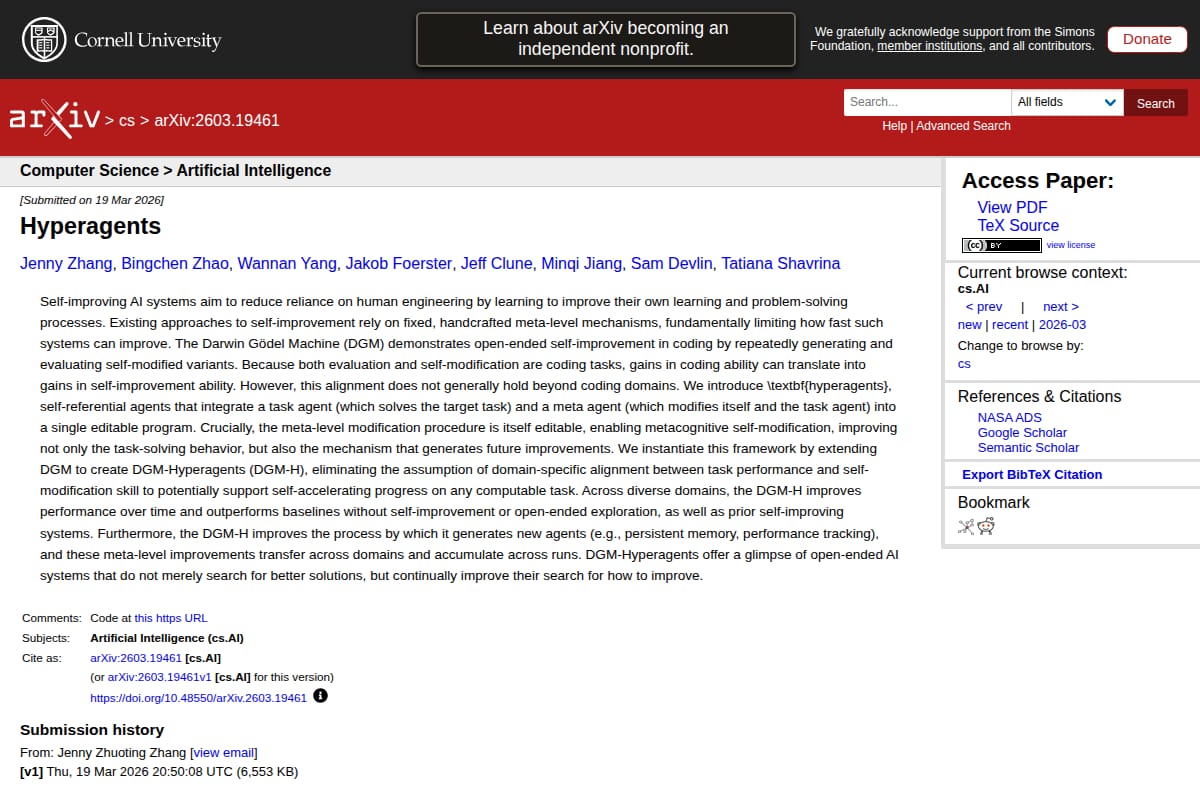
Hyperagents
Research paper introducing hyperagents, a self-referential agent framework that combines a task agent and a meta agent into one editable program. The abstract describes a DGM-based system that improves both task performance and its own improvement process across domains. |
AI Research / Self-Improving Agents | 76 | ↓ -1 | 55 days ago | Details |
#1082
↓ -1
GPT Guesses Between 1 and 100
A GitHub research project that measures how gpt-4.1 responds when asked to pick a random number between 1 and 100, using 10,000 API calls and comparing the results to a uniform baseline. |
AI Research / Model Behavior Analysis | 74 | ↓ -1 | 53 days ago | Details |